Eltupe Technology And Software Updates
Eltupe Technology And Software Updates
Related Articles


As the amount of data generated by businesses continues to grow, finding ways to store, manage, and analyze it has become increasingly important. Hadoop, an open-source software framework, has emerged as a popular solution for handling Big Data. In this article, we will explore how Hadoop works and its benefits.
Details
What is Hadoop?
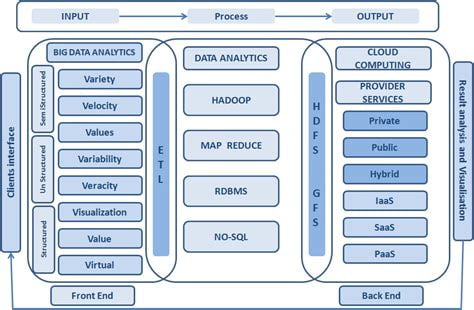
Hadoop is a distributed file system that can store and process large amounts of data. It is designed to be scalable, fault-tolerant, and cost-effective. Hadoop is made up of two main components: Hadoop Distributed File System (HDFS) and MapReduce.
How does Hadoop work?
HDFS is the storage component of Hadoop. It breaks up large files into smaller blocks and distributes them across a cluster of computers. Each block is replicated multiple times to ensure fault-tolerance. MapReduce is the processing component of Hadoop. It allows users to write programs that can process data in parallel across the cluster.
What are the benefits of using Hadoop for Big Data?
One of the main benefits of Hadoop is its scalability. As data grows, more nodes can be added to the cluster to handle the increased workload. Hadoop is also fault-tolerant, meaning that if a node fails, the data is replicated on other nodes. Hadoop is also cost-effective, as it can be run on commodity hardware. Additionally, Hadoop is flexible and can handle a variety of data types, including structured, semi-structured, and unstructured data.
Who uses Hadoop?
Hadoop is used by a variety of companies, including Yahoo, Facebook, and eBay. It is also used by government agencies, such as the NSA and NASA. Hadoop can be used in a variety of industries, including finance, healthcare, and retail.
What are some common use cases for Hadoop?
Hadoop can be used for a variety of Big Data use cases, including:
- Data warehousing
- Log processing
- Recommendation engines
- Sentiment analysis
- Fraud detection
- Image and video analysis
What are some alternatives to Hadoop?
There are several alternatives to Hadoop, including Apache Spark, Apache Storm, and Apache Flink. These frameworks offer similar functionality to Hadoop but may have different strengths and weaknesses depending on the specific use case.
FAQ
What are the system requirements for running Hadoop?
Hadoop can run on a variety of hardware configurations, but it is recommended to have at least three nodes to ensure fault-tolerance. Each node should have at least 8GB of RAM and 2-4 cores.
Is Hadoop difficult to learn?
Hadoop has a steep learning curve, but there are many resources available online to help beginners get started. Additionally, many universities offer courses on Hadoop and Big Data.
Is Hadoop only for Big Data?
Hadoop is designed to handle Big Data, but it can also be used for smaller datasets.
Is Hadoop secure?
Hadoop has several security features, including authentication, authorization, and encryption. However, it is important to ensure that these features are properly configured to ensure the security of the data.
What programming languages can be used with Hadoop?
Hadoop can be programmed using a variety of languages, including Java, Python, and Scala.
Is Hadoop suitable for real-time processing?
Hadoop is not designed for real-time processing, as it can take several minutes to process data. For real-time processing, Apache Storm or Apache Flink may be more suitable.
What is the future of Hadoop?
The future of Hadoop is uncertain, as new technologies continue to emerge. However, Hadoop is still widely used and is expected to remain a popular solution for Big Data processing for the foreseeable future.
How much does Hadoop cost?
Hadoop is open-source software and is free to use. However, there may be costs associated with hardware, maintenance, and support.
Pros
Hadoop offers a variety of benefits for Big Data processing, including scalability, fault-tolerance, and cost-effectiveness. It also offers flexibility in handling a variety of data types and is widely used in a variety of industries.
Tips
If you are new to Hadoop, start by learning the basics of HDFS and MapReduce. There are many resources available online, including tutorials, videos, and documentation. Additionally, consider taking a course on Hadoop and Big Data at a university or online platform.
Summary
Hadoop is an open-source software framework that is designed to handle Big Data processing. It consists of two main components: HDFS and MapReduce. Hadoop offers scalability, fault-tolerance, and cost-effectiveness, and is widely used in a variety of industries. However, there are alternatives to Hadoop, and it has a steep learning curve. By understanding the basics of Hadoop and the benefits it offers, businesses can make informed decisions about whether it is the right solution for their Big Data needs.