Eltupe Technology And Software Updates
Eltupe Technology And Software Updates
Related Articles



Introduction
Welcome to this exclusive article on the convergence of big data, cloud computing, and the powerful technologies Kafka and Flink. In the digital era, the ever-increasing volume of data has become a significant driving force for organizations across various industries. To keep up with this data deluge, businesses are turning to cutting-edge technologies that can efficiently process, analyze, and derive meaningful insights from massive datasets. This is where big data and cloud computing, accompanied by Kafka and Flink, come into the picture.
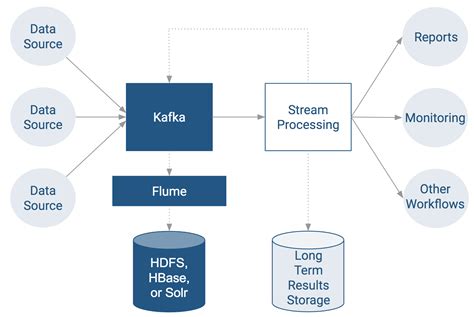
With the advancement of cloud computing, storing and processing gigantic datasets has become more affordable, flexible, and scalable. This has paved the way for businesses to leverage big data technologies such as Kafka and Flink to handle their data-intensive workloads seamlessly. Kafka, a distributed streaming platform, allows users to publish and subscribe to streams of records, making it a natural fit for real-time big data processing. On the other hand, Flink, an open-source stream processing framework, enables high-throughput, low-latency data processing with fault-tolerance capabilities.
Featured Image
Strengths and Weaknesses
Strengths
1. Scalability: One of the key advantages of big data and cloud computing with Kafka and Flink is their ability to handle massive scalability requirements, allowing businesses to grow and process ever-increasing volumes of data without significant infrastructure changes.
2. Real-time Analytics: Kafka and Flink enable organizations to process and analyze data in real-time, empowering them to make data-driven decisions on the fly. This capability is particularly valuable in industries such as finance, e-commerce, and IoT, where real-time insights can drive competitive advantages.
3. Fault-Tolerance: Both Kafka and Flink are designed to handle failures gracefully. They provide fault-tolerant features that ensure data integrity and system availability even in the face of hardware or software failures.
4. High Throughput and Low Latency: Flink’s streaming processing capabilities and Kafka’s publish-subscribe model enable high throughput and low latency data processing. This makes them ideal for use cases where near real-time streaming analytics is essential, such as fraud detection or predictive maintenance.
5. Flexibility: Kafka and Flink offer flexibility in terms of data sources and integration. They can seamlessly integrate with a wide range of data systems, applications, and programming languages, making it easier for businesses to adopt and adapt to their specific needs.
6. Cost-Effective: Cloud computing and the pay-as-you-go pricing model reduce infrastructure costs and eliminate the need for upfront investments in hardware. This cost-effectiveness enables businesses of all sizes to access and utilize big data technologies without breaking the bank.
7. Community Support: Both Kafka and Flink have strong and active open-source communities. This ensures continuous development, improvement, and support, making them reliable solutions for businesses in the long run.
Weaknesses
1. Complexity: Implementing and managing big data and cloud computing technologies like Kafka and Flink can be complex. It requires skilled professionals and a deep understanding of the underlying concepts and best practices.
2. Learning Curve: Due to the complexity involved, there may be a steep learning curve for organizations transitioning to big data and cloud computing with Kafka and Flink. Adequate training and upskilling of employees are crucial to ensure successful adoption.
3. Data Security: As with any technology involving the storage and processing of data, ensuring data security and privacy is paramount. Organizations need to implement robust security measures to protect sensitive data from unauthorized access or breaches.
4. Compatibility: While Kafka and Flink offer great flexibility, ensuring compatibility with existing systems and technologies can sometimes be challenging. Organizations may face integration issues and require additional customization to fit their specific requirements.
5. Operational Overhead: Running big data and cloud computing solutions efficiently requires dedicated infrastructure, monitoring, and maintenance. This may add operational overhead and costs, especially for organizations with limited resources or expertise.
6. Data Quality: Processing vast amounts of data may expose potential issues with data quality. Inaccurate or inconsistent data can affect the accuracy and reliability of the insights derived from big data and cloud computing solutions. Appropriate data cleansing and validation processes need to be in place.
7. Vendor Lock-In: Depending heavily on specific technologies like Kafka and Flink may result in vendor lock-in. Organizations should consider strategies to minimize this risk and ensure they have the flexibility to switch or integrate with alternative technologies when needed.
Frequently Asked Questions
1. What is the role of Kafka in big data and cloud computing?
Kafka plays a crucial role in big data and cloud computing by providing a distributed streaming platform that efficiently handles real-time data processing, messaging, and event streaming. It acts as a highly scalable and fault-tolerant messaging system, serving as a backbone of streaming data pipelines.
2. How does Flink contribute to big data and cloud computing?
Flink is an open-source stream processing framework that seamlessly integrates with big data and cloud computing technologies. It enables high-throughput, low-latency processing of streaming data, making it ideal for real-time analytics, machine learning, and complex event processing use cases.
3. Can big data and cloud computing with Kafka and Flink benefit small businesses?
Yes, big data and cloud computing with Kafka and Flink can benefit small businesses. The scalability, affordability, and flexibility offered by cloud computing make it feasible for small businesses to leverage big data technologies without significant upfront investments. Kafka and Flink enable real-time analytics and insights that can drive business growth and competitiveness.
4. Are there any alternatives to Kafka and Flink for big data processing?
Yes, there are alternative technologies for big data processing, such as Apache Spark, Apache Storm, and Apache Samza. However, Kafka and Flink offer unique features and capabilities that make them popular choices for real-time streaming data processing and analytics in big data and cloud computing environments.
5. How can organizations address data security concerns in big data and cloud computing?
Organizations can address data security concerns in big data and cloud computing by implementing robust security measures. This includes encryption of data at rest and in transit, access controls and user authentication, regular security audits, and compliance with data protection regulations and standards.
6. Is it necessary to have a dedicated team for managing big data and cloud computing with Kafka and Flink?
Having a dedicated team with the necessary skills and expertise can greatly facilitate the successful implementation and management of big data and cloud computing with Kafka and Flink. However, organizations can also consider partnering with external service providers or investing in training programs to build internal capabilities.
7. How can businesses justify the investment in big data and cloud computing with Kafka and Flink?
Businesses can justify the investment in big data and cloud computing with Kafka and Flink by considering the potential benefits, such as improved decision-making, enhanced operational efficiency, cost savings, and gaining a competitive advantage. Conducting a thorough cost-benefit analysis and assessing the specific needs and goals of the organization can help in making an informed decision.
Conclusion
In conclusion, big data and cloud computing with Kafka and Flink offer immense potential for organizations to effectively process, analyze, and leverage valuable insights from massive datasets. By harnessing the scalability, real-time analytics, and fault-tolerance capabilities of Kafka and Flink, businesses can stay ahead of the competition and unlock new opportunities in the digital age. However, it is important to carefully evaluate the strengths and weaknesses, address data security concerns, and ensure adequate resources and expertise to maximize the benefits of this powerful combination. Embracing big data and cloud computing with Kafka and Flink can be the key to unlocking the full potential of data-driven decision-making and innovation.
Closing Words
In today’s data-driven world, big data and cloud computing with Kafka and Flink have become essential for organizations striving to remain competitive and innovative. By leveraging these technologies, businesses can uncover valuable insights, improve operational efficiency, and drive growth. So, don’t miss out on the immense advantages offered by big data and cloud computing with Kafka and Flink. Start your journey towards data excellence and embrace this powerful combination to unlock the true potential of your organization.
Disclaimer
The information provided in this article is for general informational purposes only. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability, or availability with respect to the article or the information, products, services, or related graphics contained in the article. Any reliance you place on such information is therefore strictly at your own risk. In no event will we be liable for any loss or damage including without limitation, indirect or consequential loss or damage, or any loss or damage whatsoever arising from the use of this article.
Feel free to explore more about big data and cloud computing with Kafka and Flink through the following internal links: